LensCraft
Your Professional Virtual Cinematographer
Abstract
Digital creators, from indie filmmakers to animation studios, face a persistent bottleneck: translating their creative vision into precise camera movements. Despite significant progress in computer vision and artificial intelligence, current automated filming systems struggle with a fundamental trade-off between mechanical execution and creative intent. Crucially, almost all previous works simplify the subject to a single point, ignoring its orientation and true volume, severely limiting spatial awareness during filming. LensCraft solves this problem by mimicking the expertise of a professional cinematographer, using a data-driven approach that combines cinematographic principles with the flexibility to adapt to dynamic scenes in real time. Our solution combines a specialized simulation framework for generating high-fidelity training data with an advanced neural model that is faithful to the script while being aware of the volume and dynamic behavior of the subject. Additionally, our approach allows for flexible control via various input modalities, including text prompts, subject trajectory and volume, key points, or a full camera trajectory. It offers creators a versatile tool to guide camera movements in line with their vision. Leveraging a lightweight real-time architecture, LensCraft achieves markedly lower computational complexity and faster inference while maintaining high output quality. Extensive evaluation across static and dynamic scenarios reveals unprecedented accuracy and coherence, setting a new benchmark for intelligent camera systems compared to state-of-the-art models.
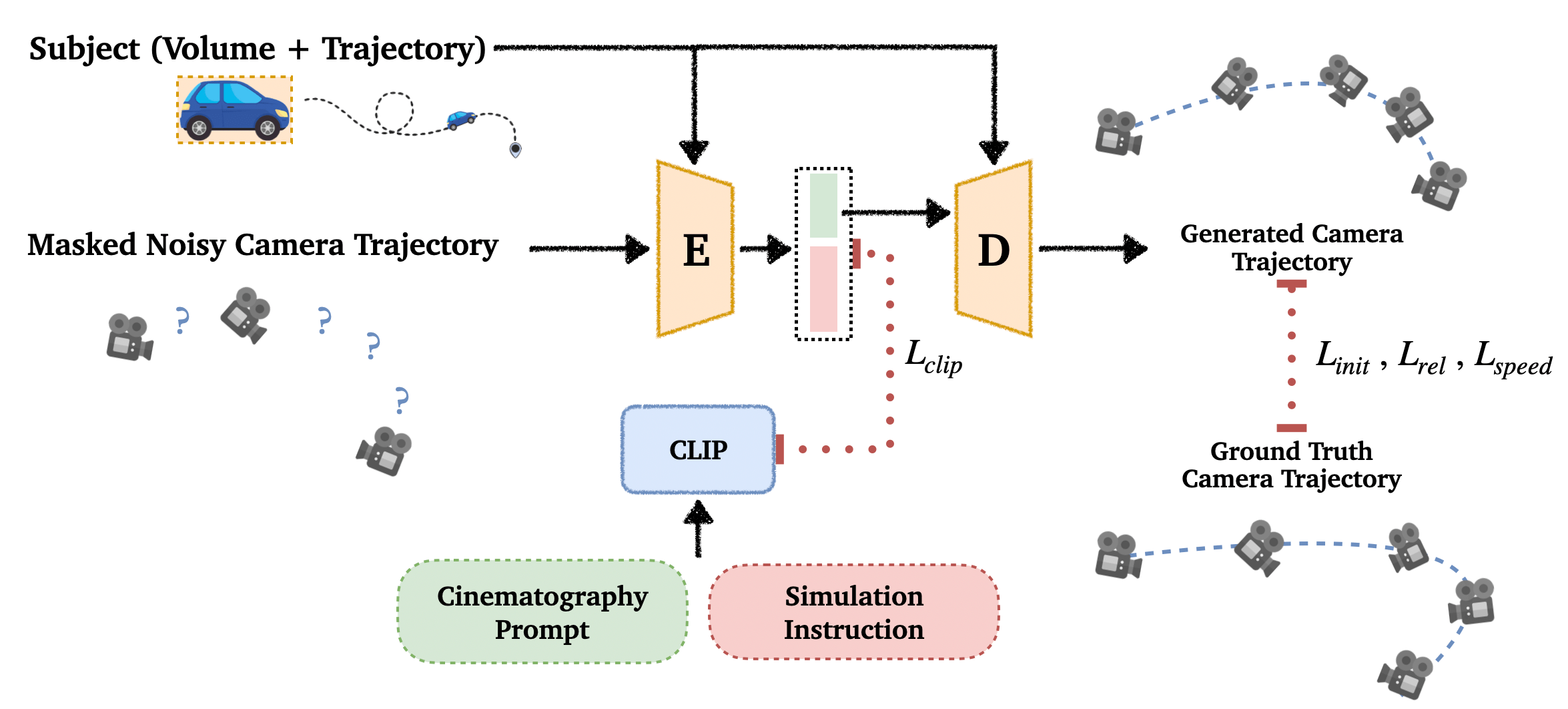
LensCraft Pipeline
LensCraft at a Glance
Introduction
The language of cinematography extends far beyond simple camera operations, encompassing a rich representation of visual storytelling elements that can express distinct styles, perceived motions, emotional resonances, and visual perceptions. While this sophisticated language holds the capacity to translate a director's narrative vision into precise camera movements—just as it does in real-world filmmaking—it demands exact alignment and precise execution from automated systems. Each camera movement must not merely follow rules, but rather embody the director's intent with the finesse of an experienced professional cinematographer, whether capturing the subtle tension in a dramatic scene or the dynamic energy of an action sequence.
Current automated approaches fall into two limiting categories. Traditional methods sacrifice creative potential for predictability, reducing the rich language of cinematography to mechanical executions of predefined rules, constraints, and objectives. On the other hand, more recent learning-based approaches, while capable of generating complex camera sequences, often get lost in this complexity due to imbalanced training data distributions and insufficient richness in their learning examples. As a result, these methods struggle to maintain professional quality while staying faithful to user instructions, producing sophisticated sequences that drift from the intended cinematographic direction. This fundamental disconnect becomes particularly apparent when handling diverse filming scenarios, where the balance between professional execution and precise alignment with user intent becomes crucial.
Additionally, one crucial aspect that prior models often overlook is the impact of subject volume. In real-world filmmaking, the scale and physical presence of the subject—whether filming from an ant's perspective or capturing a building—significantly influence the camera's behavior and trajectory. However, most prior works simplify the subject by representing it as a point or by modeling it in a fixed specific form. This oversimplification, due to limitations in dataset complexity, fails to capture the true dynamics of subject volume, which is essential for generating realistic and context-aware camera movements.
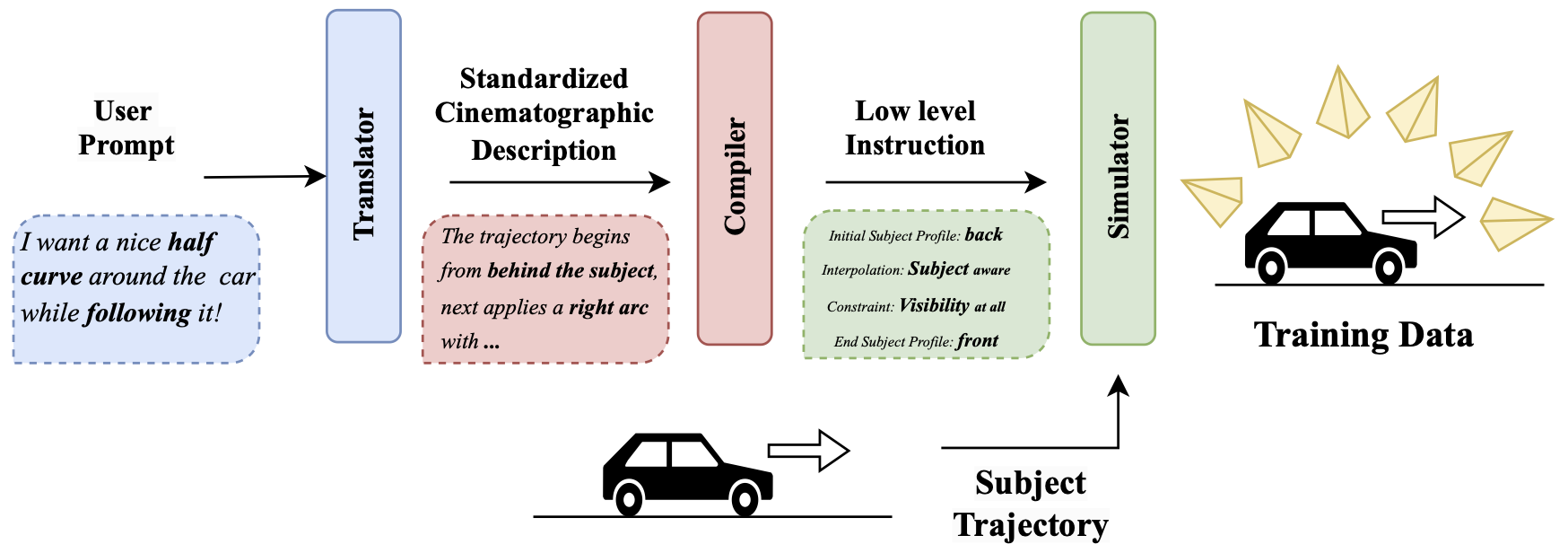
This fundamental disconnect motivated us to develop LensCraft, a novel approach that bridges the gap between professional cinematographic execution and precise user control. In addressing this challenge, we first identified two key obstacles: the absence of a unified, comprehensive standard for a representative cinematographic language, and the lack of a balanced, large-scale, volume-aware dataset that covers the full spectrum of camera movements. To overcome these challenges, we designed a standard cinematography language to provide a unified foundation for our approach and developed the first fully open-source, carefully designed simulation framework to generate a diverse and well-balanced dataset, serving as the foundational pillars required for our model.
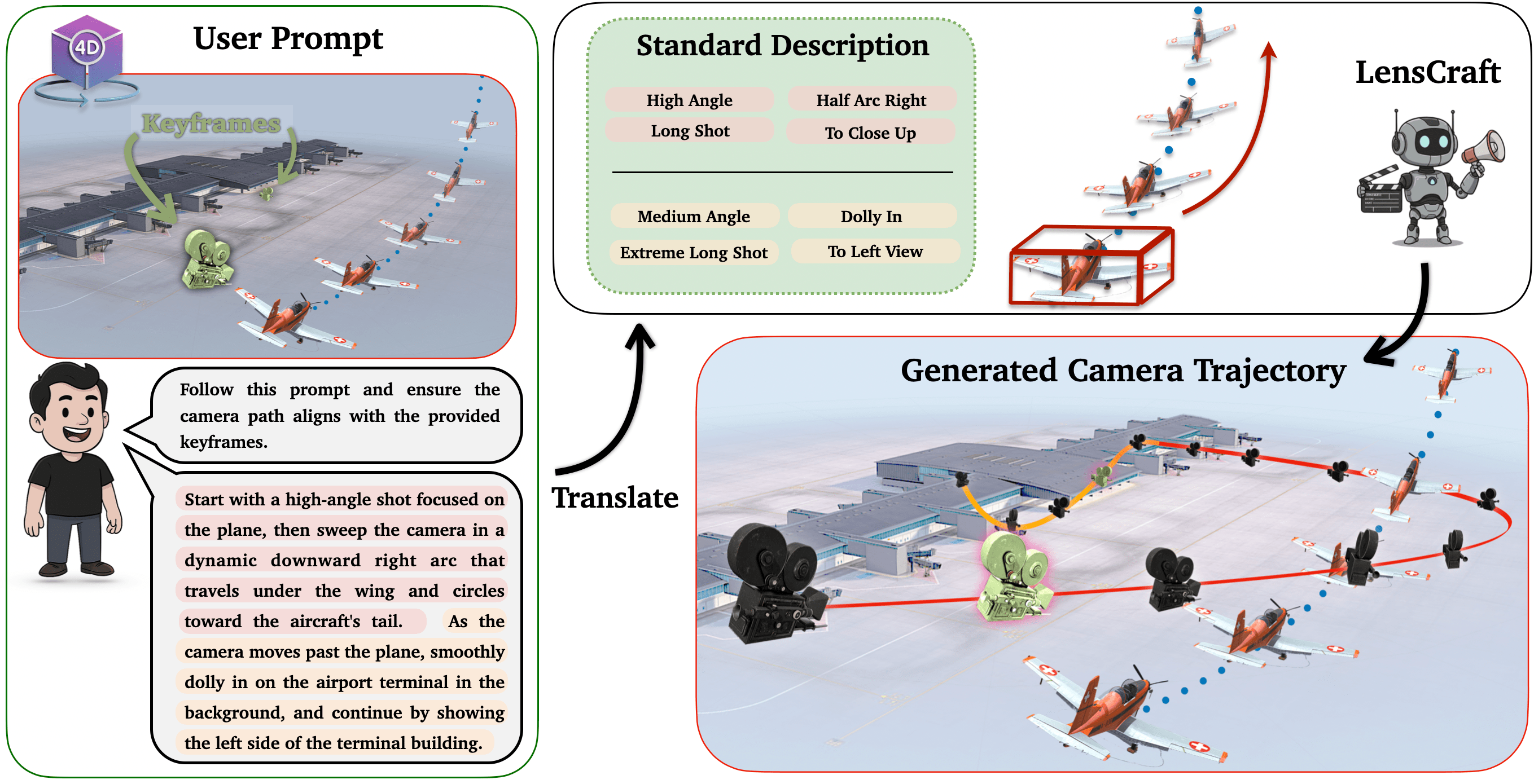
Leveraging this backbone to combine the solidity of traditional rule-based methods with the creativity of neural models, we designed a lightweight transformer-based architecture that learns and generates complex simulated movements, using only a text prompt or optional key frames, enabling it to produce robust and creatively aligned outputs. To accommodate a wider range of user instructions, we also provide an appendix that converts arbitrary user prompts into our standardized cinematographic description.